Small experiment with Git as a data storage
Lets imagine you need to collect a small data about, lets say, your users, or some trivial application metrics. Also, you will collect the data for only limited period of time. So, the only requirement of the solution is to be able to keep the data safe, and have an easy access to it, better without installing extra software. Consider, as well the operational burden you want to minimize, and utilize as less paid services and servers as possible. What would be your storage of choice? ;) It sounds like that storing data in a file would be a reasonable option to go, but how to protect against data loss? The answer is...
Git
Indeed, why not to use Git to keep the changes in the file, and rely on Github or Bitbucket to keep the data safe. Easy access? Obviously, just a plain text file, you can view in the browser online. One of the challenge of implementing your own file based datastore, is to ensure, write access from multiple threads is protected, so no data corruption could happen, and as well do not block the web requests allow the server to fire a task and continue handling other incoming requests. Sounds, like a queue? And it is.
core.async
Concept of channels is not unique to Clojure. core.async was inspired by Go goroutines, which are based on CSP anyway. Every time the new request is coming I fire a new (go)command which puts the data into store channel.
(POST "/" {body :body}
(let [email (:email body)
ok-response (response/response "")]
(if (validate/possibly-email? email)
(do
(async/go (async/>! store/store-chan (clojure.string/trim email)))
ok-response)
(response/status ok-response (:bad-request response-codes)))))
There are 5 go workers who are waiting for the data available in the channel, get it and add it into the memory set.
(defn- start-go-workers [num]
(dotimes [_ num]
(async/go (while @running?
(let [email (async/<! store-chan)]
(swap! memory-emails conj email)))))
(log/info "All go workers are started"))
(start-go-workers 5)
Concurrency techniques
Dealing with multiple threads and concurrency is always a little bit of a challenge. There are different languages (Go, Java, Clojure) which provide its own constructs to deal with the concurrent programming, also in some languages it is easier to do than in others, but no matter which language is used it always requires thinking.
As I was using Clojure to develop this application, I will cover the Clojure constructs below I found handy while working on the application:
- meet the atom (the simple Clojure concurrent construct)
(def ^{:doc "In-memory emails storage for collecting 'working' emails until they are flushed into the persistence Git-based storage"} memory-emails (atom #{})) - CAS (compare-and-swap) atomically add the new value into the set
(swap! memory-emails conj email) - atomically trying to flush the memory set (it might not succeed, but there is no risk of data loss)
(swap! memory-emails #(apply disj % new-emails)) - exclusive lock to write into the file, also I don't need to lock on
@memory-emailsatom, as well it is not necessary to wrap the lock intotry/finallyas in Java, as it will be released in all circumstances(locking store-file ...) delay/forceto postpone repo initialization or initialize once no matter from how many threads it has been called, and be sure it will be evaluated only once (if you are familiar with Go, it has the same conceptsync.Once) (one of my favorite features together withpromise/deliver, although not used in this application)(def ^:private repo (delay (if (.exists (io/file local-repo-path)) (load-repo local-repo-path) (:repo (git-clone-full (env/repo-url) local-repo-path)))))flush-running? atomto prevent multiple flush to occur at the same time, still happens, but less, if do without and reset the state intry/finallyblock:(try (reset! flush-running? true) (force repo) (let [stored-emails (if (.exists (io/file store-file)) (clojure.string/split (slurp store-file) #"\n") []) new-emails @memory-emails emails-to-store (-> (concat stored-emails new-emails) distinct sort)] (if-not (= (count emails-to-store) (count stored-emails)) (do (git-store emails-to-store) (log/info "Data is flushed")) (log/info "Nothing to flush, no new unique emails")) ; clean up flushed emails from memory-emails (swap! memory-emails #(apply disj % new-emails))) (finally (reset! flush-running? false)))
Flushing the data
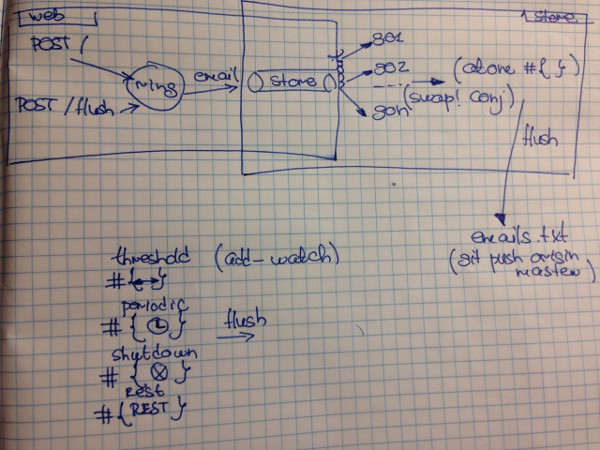
As the data is kept in memory, there should be ways to flush it to the persistence store. The available choices are: periodically (using internal scheduler), on reaching configured threshold, on application shutdown and manually (by providing, lets say, a REST endpoint).
All of them are covered below:
- Periodically (
ScheduledExecutorServicecould be used instead):(defn- start-flush-scheduler [] (async/thread (log/info "Flush scheduler started") (loop [last-flushed-at (LocalDateTime/now)] (when @running? (let [now (LocalDateTime/now) elapsed-mins-since-last-flush (.between ChronoUnit/MINUTES last-flushed-at now) sleep-mins (max 0 (- (env/flush-interval-mins) elapsed-mins-since-last-flush))] (log/trace "Elapsed time since last flush" elapsed-mins-since-last-flush "mins") (log/trace "Sleeping for" sleep-mins "minutes") (.sleep TimeUnit/MINUTES sleep-mins) (recur (if (zero? sleep-mins) (do (flush :scheduler) (LocalDateTime/now)) last-flushed-at))))))) - On shutdown:
(defn- register-shutdown-hook [] (log/info "Register shutdown hook") (.addShutdownHook (Runtime/getRuntime) (Thread. #(do (log/info "Shutdown...") ; waiting for any currently running store call to finish (locking store-file (flush :shutdown) (reset! running? false)))))) - On threshold reached, with handy
(add-watch memory-emails ::threshold flush-on-threshold):(defn- flush-on-threshold [key _ _ emails] (when (>= (count emails) (env/flush-threshold)) (log/debug "Threshold is reached, flushing") (async/go (flush :threshold)))) - And manually with REST call (if enabled):
(let [web-flush-command (env/web-flush-command) web-flush-command-enabled? (not (zero? (env/web-flush-command-enabled))) ok-response (response/response "")] (when web-flush-command-enabled? (log/info "Web flush command is available through" (str "/" web-flush-command))) (POST (str "/" web-flush-command) [] (if web-flush-command-enabled? (do (async/go (store/flush :web)) (response/response "")) (response/status ok-response (:forbidden response-codes)))))
To summarize everything above in a nice :) overview diagram below using pen and paper:
Working with environment variables
I really like the ideas behind 12 factor app, which I follow in any application I develop as much as possible. I will not go into the details about all the factors, here I will focus on the environment variables, as it is the one I always implement (Store config in the environment). And this application is not an exception.
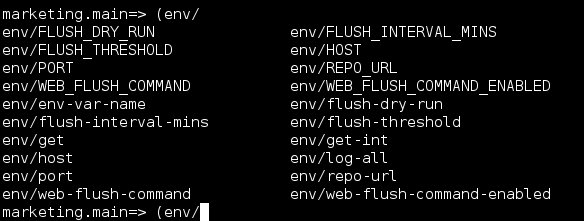
Clojure again helped here a lot. Below are all the environment variables the application supports.
(def ^:private all-env-vars [{:name ::PORT :default 3000 :int? true}
{:name ::HOST :default "localhost"}
{:name ::REPO_URL}
{:name ::WEB_FLUSH_COMMAND :default "flush"}
{:name ::WEB_FLUSH_COMMAND_ENABLED :default 1 :int? true}
{:name ::FLUSH_INTERVAL_MINS :default 10 :int? true}
{:name ::FLUSH_THRESHOLD :default 10000 :int? true}
{:name ::FLUSH_DRY_RUN :default 0 :int? true}])
I define the environment variable in a private vector, and as Lisp (and so Clojure) makes it easy (and encourages?) to build an application specific DSL, here I introduce extra properties like :default, and :int? where it is necessary.
And then another interesting part of the Clojure comes into play - programs generating programs. Yes, it sounds like a macro, and I've started with a macro first, but as a rule says, if you can solve the problem without a macro it is better to do so. Found out that it is possible to intern the current namespace and add extra var in runtime into it.
Another aspect of Clojure which was useful in this context is (with-meta).
So, all together it looks like this:
(defn- defenv [vars]
(doseq [env-var vars :let [env-var-kw (:name env-var)
env-var-default (:default env-var)
env-var-int? (:int? env-var)
def-name (symbol (name env-var-kw))
defn-name (-> env-var-kw
(name)
(string/lower-case)
(string/replace \_ \-)
(symbol))]]
(intern *ns* defn-name (fn []
((if env-var-int? get-int get) env-var-kw env-var-default)))
(intern *ns* (with-meta def-name {:defn defn-name}) env-var-kw)))
This allows me to define the new environment variable in the vector above, and the code will generate the corresponding functions and keywords available in the env namespace:
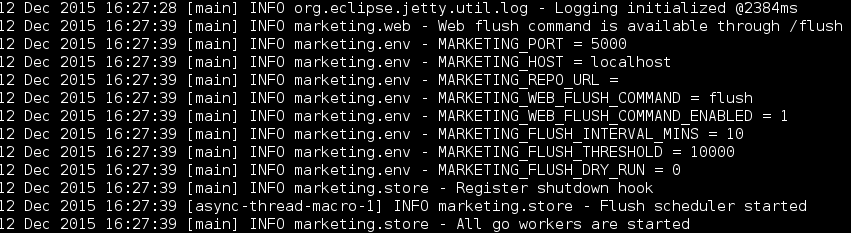
as well easily print the current values during application startup:
Also, to be honest environment part handling in this application probably is the most complex one, even though I am trying to keep it simple. And this is exactly the part for which I have unit tests:
...
(deftest env-flush-interval-mins
(is (= 10 (env/flush-interval-mins))))
...
(deftest env-var-names
(testing "Environment variables actual names"
(are [expected actual]
(= expected (env/env-var-name actual))
"MARKETING_PORT" env/PORT
"MARKETING_HOST" env/HOST
"MARKETING_REPO_URL" env/REPO_URL
"MARKETING_WEB_FLUSH_COMMAND" env/WEB_FLUSH_COMMAND
"MARKETING_WEB_FLUSH_COMMAND_ENABLED" env/WEB_FLUSH_COMMAND_ENABLED
"MARKETING_FLUSH_INTERVAL_MINS" env/FLUSH_INTERVAL_MINS
"MARKETING_FLUSH_THRESHOLD" env/FLUSH_THRESHOLD
"MARKETING_FLUSH_DRY_RUN" env/FLUSH_DRY_RUN)))
Wait, and where is the Git?
git-store function is where all the Git operations are happening:
(defn- git-store [emails reason]
(locking store-file
(spit store-file (clojure.string/join "\n" emails))
(git-add @repo "emails.txt")
(let [msg (str "Store " (count emails) " collected emails (" reason ").")]
(git-commit @repo msg {:name "Marketing Bot" :email ""}))
(let [push-cmd (.push @repo)
dry-run? (not (zero? (env/flush-dry-run)))]
(when-not dry-run?
(.call push-cmd)))))
where @repo itself is defined like
(def ^:private repo (delay (if (.exists (io/file local-repo-path))
(load-repo local-repo-path)
(:repo (git-clone-full (env/repo-url) local-repo-path)))))
This is all it takes to commit and push the changes into the remote repository :)
Sounds cool, but how do you know it works?
First of all, Clojure makes concurrent programming easier, although not easy, but it helps in this area a lot by providing useful concurrency primitives, and being immutable by default.
Second is testing :) Well, in that kind of applications (and in general) I prefer system/integration testing (also trying minimize the use of mocks during unit testing being a on classical TDD side as it is described by Martin Fowler).
Even though there are base unit tests in the application, they don't test the full workflow, but individuals parts (actually just everything related to using environment).
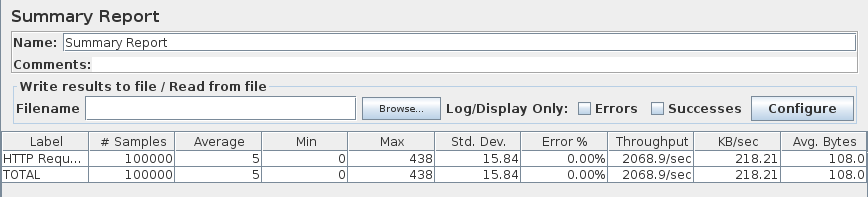
To test the complete workflow here is a JMeter script which does run 100 threads 1000 times simultaneously sending a POST request, so triggering multiple writes and flushing happen at the same time. In the end it is enough to compare the number of entries in the generated file to be equal to the total number of concurrent requests done by JMeter.
wc -l emails.txt should be equal to n-1 (n-1 as wc counts new lines, where n is total number of requests done):
This is how git log will look like during JMeter script execution.
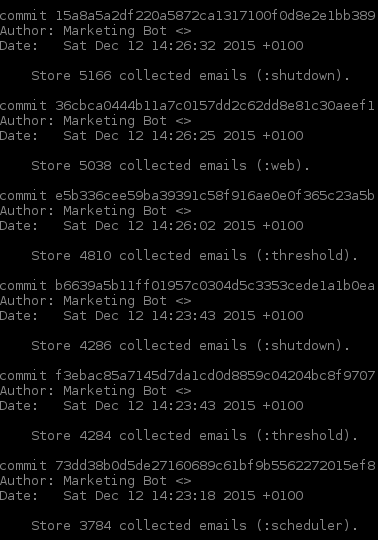
So, the final result...

Clojure and REPL driven development overall experience
I was using Clojure already for a while, and every time it is fun and joy to work with. Overall experience is really positive.
Clojure proved to be a really practical language allows focusing on the business problem rather than language constructs.
With Clojure I found that most of the time I think about the problem at hand, and I don't notice the language, but rather express my thoughts using the language.
Nice thing observed, that Clojure code is like a book. If you just quickly scan the code (or book) there is no much sense. But, if you actually start reading, and focusing on it, suddenly the code/book starts making perfect sense and becomes very readable.
The only still not well explored area of Clojure is testing. Personally, I am trying to avoid mocking, in favor of pure unit tests, and real integration tests, skipping mocking whenever possible. And it seems like the way to go with Clojure as well.
I've just recently read a chapter Testing Clojure from Clojure Applied book, and I agree with authors:
Our goal is to maximize the value (in terms of coverage, bugs found, and reduced risks) with respect of the effort (for both initial creation and ongoing maintenance). Generally a mixture of techniques yields the best balance of returns, cost and risk.
and
No one technique detects every problem. Strategic investments in a variety of testing techniques are the bes way to get a great return on your testing effort.
And enjoyed the great symbiosis with the hosting system, which is not a surprise, considering it was one of the main design goal of Clojure.
What has not been covered
I have not covered web part using Ring, as well as deployment procedure using Docker. If you are interested to know more check the source code on the GitHub.