Value of automation
For the last two days apart from other things I was busy with, I was working on infrastructure automation using Ansible. Why it is important, and why it could be difficult? Keep reading :)
Value of automation
I believe you all agree, that having a reproducible build or reproducible behaviour is a good thing. When you can rely on the results you've already seen. And can easily achieve those well results whenever you need them.
Same holds for the infrastructure automation. When firing up a new cloud environment (be it AWS EC2, DigitalOcean, literally anything) - by running the automation script against that environment - you expect to get the very same setup you trust and tested before in a few minutes or less.
Although it is not all about the speed of how fast you can get the environment ready, but about the confidence, trust and peace in some sense. That you know that the machine is in control, and every change is captured.
Why it could be difficult to do
I found it is tempting to take a shortcut and do ssh and apply some small tweaks or changes, because it is faster (in a short term) rather than sit, think and transform those steps into the automation code. Which takes time (how much of the time, depends on the tool you use). But in the longer run it will pay off.
So, automation is all about the long term value vs short term convenience.
What else you can do with infrastructure automation (continuous delivery and rolling update)
Maybe it is not about infrastructure automation, but about the tool, as using the very same tool (in my case Ansible), you can come with a complete CI/CD pipeline, i.e. integrate the tool with CI system, like Jenkins, for example. From where you will do a continuous delivery - deliver the application either to the staging environment, where you can run the end to end integration tests, and even deploy to production after if those tests were succeeded.
So, in a sense you will do all of 3 together: test, release, and deploy. And "deploy" part is where automation tool can help. But to be able to do this, you should have the infrastructure automation in the first place (obviously not necessarily, but it helps if you have it, and you can use the advantage of its existence).
Migrating from Ansible 1 to Ansible 2
While I was developing the infrastructure automation for our backend, I was using my personal project ididitagain as a getting started template. Although when I originally developed it I used the latest official release which was Ansible 1.x, but here upgraded to Ansible 2.1.
These are some challenges (or new features:) I've encountered while doing so.
First to upgrade to Ansible 2.1 I have to install cryptography (sudo pip install cryptography), for which I have to install libffi6 (sudo apt-get install libffi6) (it might be different for your environment). It was a minor thing although.
Secondly, and which was a little bit time consuming both fix and find out about. This is so called "dynamic includes". When I could not understand why my "included" handler was not invoked when it was notified.
Why it was time consuming? Because, it was not mentioned anywhere as a breaking compatibility feature. But it is. Nowhere in the doc, even not in the Porting Guide, even the concept of the "dynamic include" was not clear explained or mentioned anywhere.
Although to be fair, the following was mentioned in Playbooks Intro:
You cannot notify a handler that is defined inside of an include. As of Ansible 2.1, this does work, however the include must be static.
But, didn't go any further explaining what it breaks, and what does it mean to be "static", and what is the "dynamic". And how you actually fix it (an example, would be helpful).
I found this Google Groups discussion to be exactly about this . And I really liked these comments from one of the participant:
James do you have an adoption rate of 2.0 compared to older versions? 2.0 is out for just a few months and older versions which use static includes have been out for years now and people are used to them working that way. But more importantly how many of those who switched to 2.0 are really using dynamic includes, so how many playbooks would really get broken? I guess most of the people using 2.0 had more trouble with dynamic includes than fun.
You should also think of the new users, since 2.0 basically broke the include statement and now in 2.1 you want to leave it broken by default. So future users will now always have to write static: yes for every include (except the dynamic ones, which are far less used) if they wanted their plays to behave as they expect them to work. Wouldn't the documentation be much easier for new users if the first time you mention a dynamic include is when you actual need it and not the first time you show them a simple include. So basically this doc page http://docs.ansible.com/ansible/playbooksroles.html#task-include-files-and-encouraging-reuse, which is one of the first pages new users read, will have to be changed so that it adds static: yes and you would need to explain the concept of a static/dynamic include to a new user, who just learned that there is an include statement. But if you left them to be static by default, then you would need to change basically one part of the documentation and mention it the first time you need a dynamic one which is here http://docs.ansible.com/ansible/playbooksloops.html#loops-and-includes, which as we all know is far less used than a static one and by the time the user reaches loops, they are already using Ansible.
Also what exactly is a dynamic include? I thought it is only used when you use include + with_items and when using when + include on playbook, or there are more situations when an include is useful to be dynamic?
I have one more idea/question. Would it be possible for Ansible to know all the situations when it should use a dynamic include, so that it automatically treats it as a dynamic one and threats the rest as static?
Which very well summarizes what I was thinking of. Even more surprisingly it doesn't mention those config options (task_includes_static and handler_includes_static) in the official doc Configuration file, but they are in the latest ansible.cfg in source control.
Not a big deal (and definitely not a reason for me to switch away from Ansible, it is still great), but just explicitly to mention this in the doc would help people to save some time and avoid the confusion.
So, this is what I've actually ended with:
task_includes_static = True
handler_includes_static = True
to have the same behaviour as in Ansible 1 version. Although if in the future I would need this feature, I have to use
- include: my-handler.yml static: yes
instead and disable the option above.
Why I also made task includes static? Well, even everything worked without setting this option to True, I turned it on to get rid of those blue info messages:
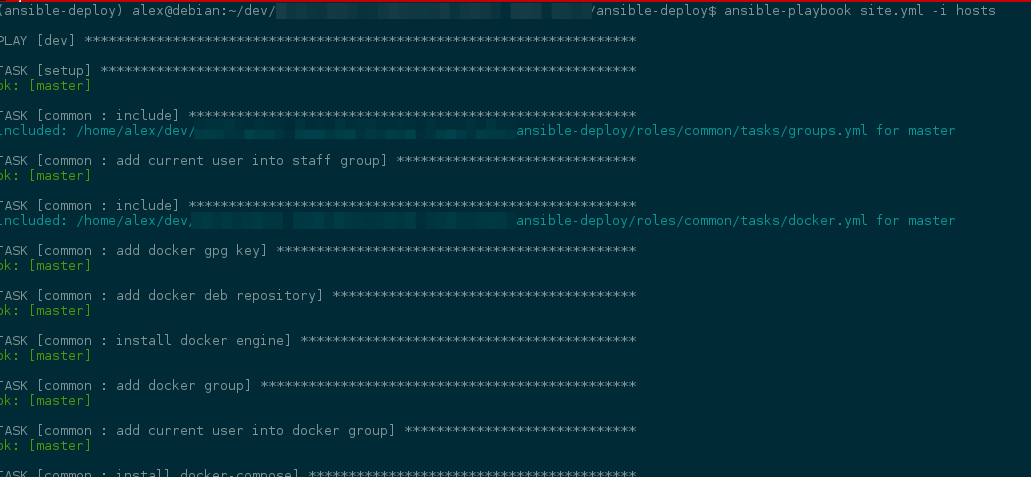
The good thing, is that Ansible respects the ansible.cfg from you current directory, so it allows to share and put the config in the source control system together with automation script. And have then the consistent behaviour between team members machines.
"Man, Ansible/Puppet/Chef are so old school, you should use Docker instead" :)
Yes, you are right :).
But, seriously. We do use Docker extensively. All our apps are Docker-ized, we use docker-compose to "orchestrate" the services we run, we run 3rd party open source products we use as docker containers. And even use docker for our integration tests.
These tools are not exclusive. They are the supplement to each other. Even if we decide to run the application in production using Docker (so utilizing, for example, AWS ECS and AWS ECR, actually we already host our images on AWS ECR), there are still use cases for Ansible, like:
- we still have to configure and install docker and docker-compose (if not using AWS ECS)
- there are config files (like logging, for example), credentials, and environment variables which vary across machines, which is better to manage with Ansible
- users, groups, locale, timezone, etc. any OS specific setup would worth to automate with Ansible as well
- there are some 3rd party open source products we most likely will not run in Docker container, but host it "manually" instead
- Ansible even has Getting Started with Docker section with official modules to work with Docker (which I am definitely going to use)
- And even more, they work on ansible-container project to be the complete toolset to operate over Docker and more (worth looking)
So, it is not about "either or", but instead the symbiosis of two useful tools.
I am not a DevOps engineer
As by reading this post and probably a few others, you might decide that I am switching my career into DevOps direction :). Nope. And on the daily basis I do backend development and coding.
I am considering myself as a software engineer, whatever it would mean. But I understand it as be able to work on any layer of the application, be responsible for the quality and architecture of the product, and balance between business needs and technical passion. I am just curious, and product development is not just about coding, it is much more. How about marketing, for example? :)
And when you are a small team (or when building a personal project), there are no other options, but being professional and experienced in complete product architecture and lifecycle, coming from database design, high-level architecture and finishing with the deployment, doing the development (actual coding) in between. And I really enjoy doing this.
And it is not that uncommon to even use multiple different languages (and Ansible, can be considered, just as another language) to develop different parts of the product. This is the reality and dynamics of the current world, which is demanding, but also a rewarding at the same time.
Cheers!